
Quickstart
Welcome & Setup Options
Android: join the Google Play open testing track and install like any other app, or sideload the signed APK from the beta program on Discord.
iPhone and iPad: install Apple TestFlight, then open the TokForge TestFlight invite and tap Install. The screenshots below are from Android; the iPhone flow mirrors them.
# Optional: sideload the APK on Android
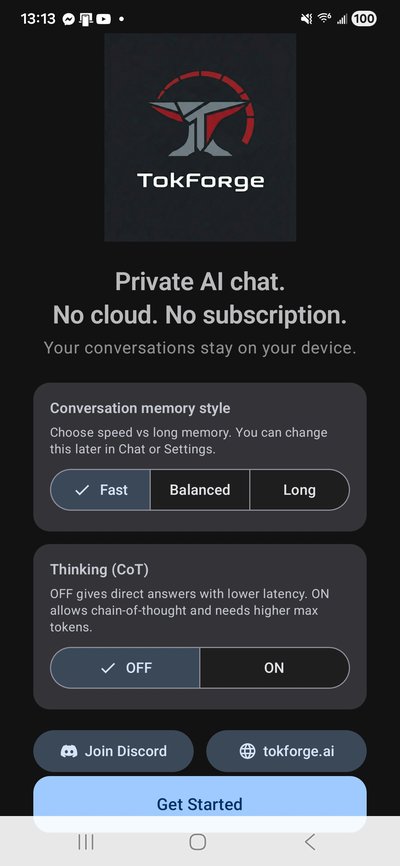
adb install tokforge-beta.apkOn first launch, you'll see the welcome screen. Choose your preferences:
- Memory Mode: Select normal or extended memory (enables background memory extraction for continuity across conversations)
- Thinking Toggle: Enable or disable thinking/reasoning mode support
Tap Get Started to begin onboarding.
Model Recommendation
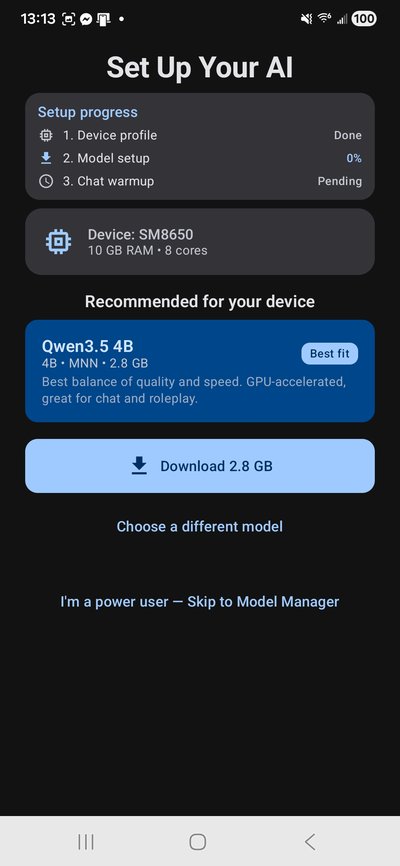
TokForge automatically profiles your device, detecting your SoC, RAM, GPU capabilities, and backend support. Based on your device tier, we recommend a model optimized for your hardware:
- 4GB RAM: Qwen3-0.6B-MNN (~0.35GB), blazing fast
- 6-8GB RAM: Qwen3-1.7B-MNN (~1.0GB) or Qwen3.5-4B-MNN (~2.3GB)
- 12GB RAM: Qwen3-8B-MNN (~4.8GB) or Qwen3.5-9B-MNN (~5.4GB)
- 16GB+ RAM: Qwen3-14B-MNN (~8.5GB) for maximum quality
The app automatically selects the best backend: MNN (GPU-accelerated on OpenCL/Vulkan) or GGUF (CPU fallback). No manual configuration needed.
Download Model
TokForge downloads models directly from Hugging Face with intelligent retry and real-time progress tracking.
You'll see:
- Live download speed and ETA
- Auto-retry with exponential backoff on network hiccups
- Disk space checks to prevent corruption
Once complete, the model is cached locally and ready to use. You can download additional models anytime from the Models tab.
Acceleration Pack (Optional)
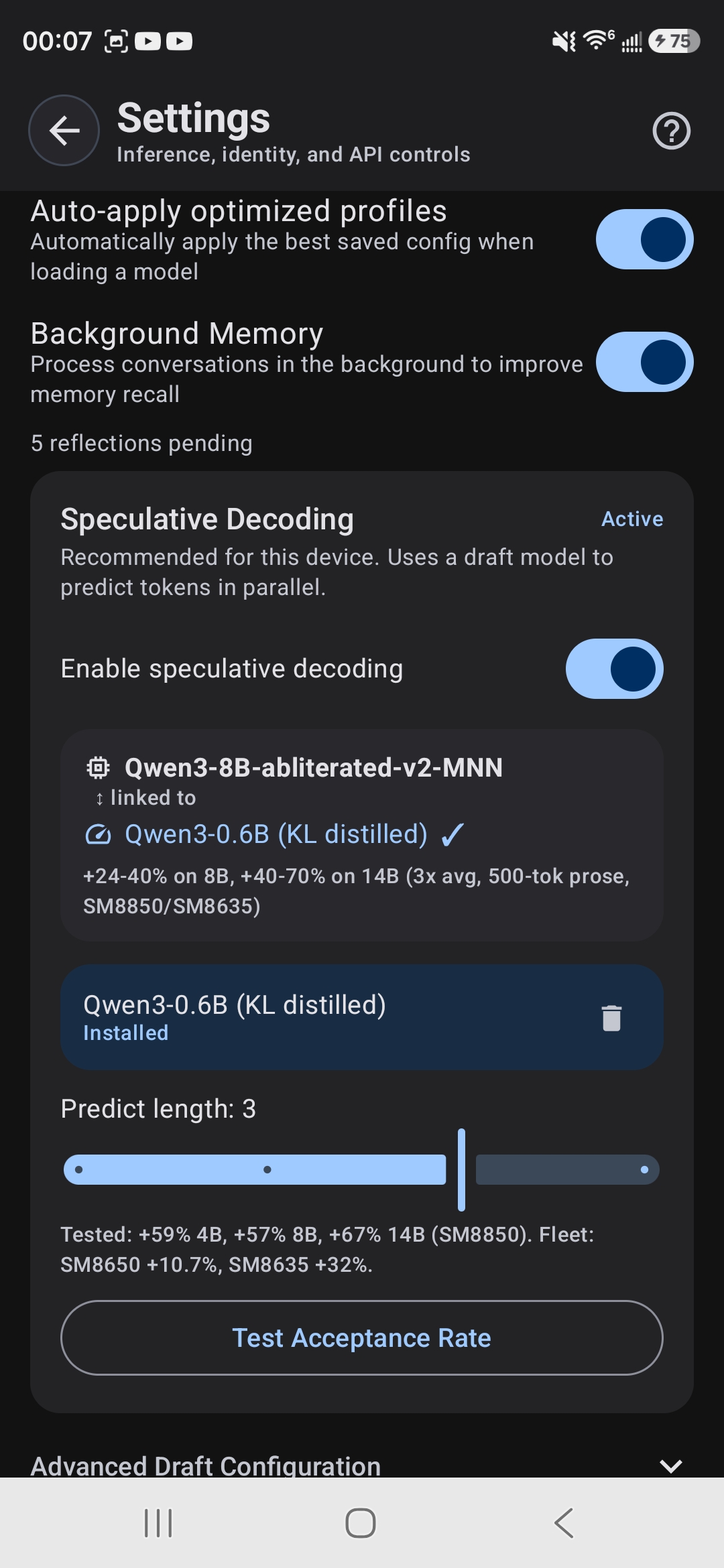
TokForge offers an optional speculative decoding acceleration pack: a lightweight draft model that runs alongside your main model to speed up generation.
On supported devices, speculative decoding can boost throughput by 20-40% with no quality loss. The draft model (typically 0.6B) is downloaded separately and toggled in Settings.
You can skip this and enable it later in Settings → Advanced.
Ready to Chat
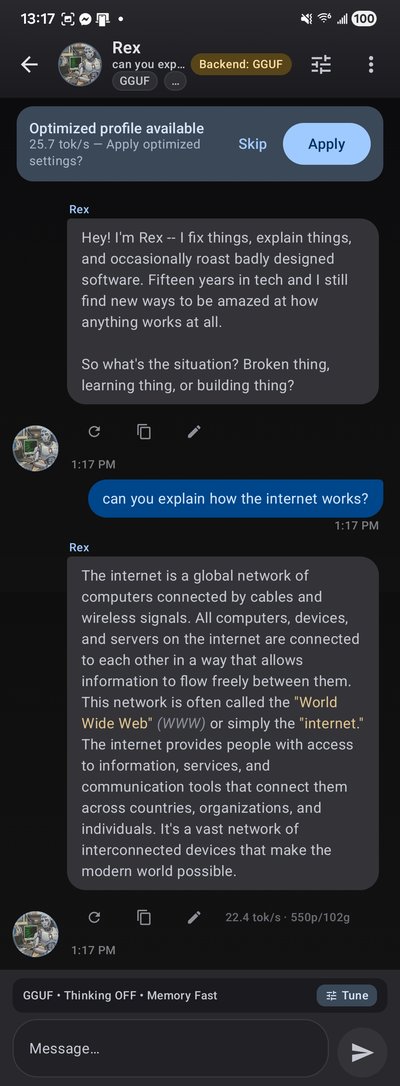
You're all set! Open a chat and start conversing. TokForge provides:
- Streaming tokens: watch the model generate in real time with live tok/s counter
- Kokoro TTS: high-quality offline text-to-speech with 11 voices (Settings → Voice)
- Per-conversation settings: adjust temperature, sampling, and other parameters per character
- Markdown rendering and code syntax highlighting
- Thinking mode: collapsible
<think>blocks show reasoning in real time - Background memory: automatically extracts and stores facts across conversations for continuity
All conversations run 100% on-device. Nothing leaves your phone.
Key Features
- Character Personas: Built-in personalities (Rex, Luna, Marcus, Aria) or import your own via TavernAI V2 format
- ForgeLab Benchmarks: Measure tok/s, prefill latency, and decode throughput across models and backends
- Three Backends: MNN (GPU), GGUF (CPU), and Remote API with automatic routing
- Voice Input: Speech-to-text for hands-free chatting
- Model Management: Download, cache, and switch models on the fly from the Models tab
System Requirements
- Android: Android 8.0+ (API 26), ARM64. 8GB+ RAM recommended (4GB minimum for the smallest models).
- iPhone and iPad: a recent iOS or iPadOS release on an A15 or newer chip. 6GB devices run small models; 8GB and 12GB unlock larger ones.
- A few hundred MB to several GB of free storage per model. The app itself is under 50MB.
Troubleshooting
Download timeouts? TokForge auto-retries with exponential backoff. Network hiccups are handled gracefully.
Slow generation? Check Settings → Advanced for backend selection. MNN uses GPU when available; GGUF falls back to CPU.
Custom characters not loading? Ensure your JSON or PNG card follows TavernAI V2 format. Invalid schemas are skipped silently.
What's Next?
- API Reference: remote device control and benchmarking endpoints
- Benchmark Methodology: how we measure performance
- Join the Beta: early access and shape the platform
Tip: TokForge is in beta. Your benchmark data helps us build the most comprehensive mobile LLM performance database. Join our Discord to share results and feedback.