
Speculative Decoding
Overview
Speculative decoding makes AI inference dramatically faster on your phone. Instead of generating text token-by-token one at a time, TokForge uses a small draft model to propose multiple tokens in parallel, while the main model verifies them in batch. The net result: responses appear in minutes instead of hours.
The Simple Version
A lightweight draft model rapidly predicts what tokens come next. The powerful main model then verifies all those predictions at once, accepting the ones that are correct and rejecting the others. This parallel verification, instead of generating token-by-token, is what creates the massive speedup.
You don't need to do anything. TokForge automatically detects which draft-target model pairs work best on your device and handles all the heavy lifting behind the scenes.
How Fast Is It?
Real-world speedups vary by device, model, and hardware. Here's what you can expect:
| Device | Model | Without Spec Decode | With Spec Decode | Speedup |
|---|---|---|---|---|
| RedMagic 11 Pro (SM8850) | Qwen3 8B | 14.05 tokens/sec | 23.5 tokens/sec | +67% |
| RedMagic 11 Pro (SM8850) | Qwen3 14B | 8.25 tokens/sec | 16.4 tokens/sec | +99% |
| OnePlus Ace 5 Ultra (D9400+) | Qwen3 8B | 9.41 tokens/sec (AR) | 10.9 tokens/sec (Spec) | +16% |
| OnePlus Ace 5 Ultra (D9400+) Vulkan AR | Qwen3 8B | 15.3 tokens/sec (Vulkan AR only) | N/A | N/A |
| OnePlus Ace 5 Ultra (D9400+) | Qwen3 14B | 5.18 tokens/sec | 6.82 tokens/sec | +32% |
On flagship hardware (2024+): Snapdragon 8 Elite sees up to 2x speedup on 14B models. MediaTek Dimensity 9400+ support is early with optimization ongoing. On older devices, spec decode is smart enough to disable itself if it wouldn't help, because we don't want slower inference.
Performance varies by:
- Device hardware (SoC, RAM, thermal conditions)
- Model size and architecture
- Input prompt length and context window usage
- Batch size and inference settings
Some devices benefit more than others. TokForge automatically detects what works best for your specific phone.
How It Works For You
Setup: Automatic
Speculative decoding requires a small draft model to run alongside your main model. TokForge handles all the heavy lifting automatically. When you download a compatible model, the necessary draft model downloads alongside it as part of the "Acceleration Pack."
You'll see a single download progress bar. The draft model is lightweight and adds minimal storage overhead to your main model.
Enable & Disable
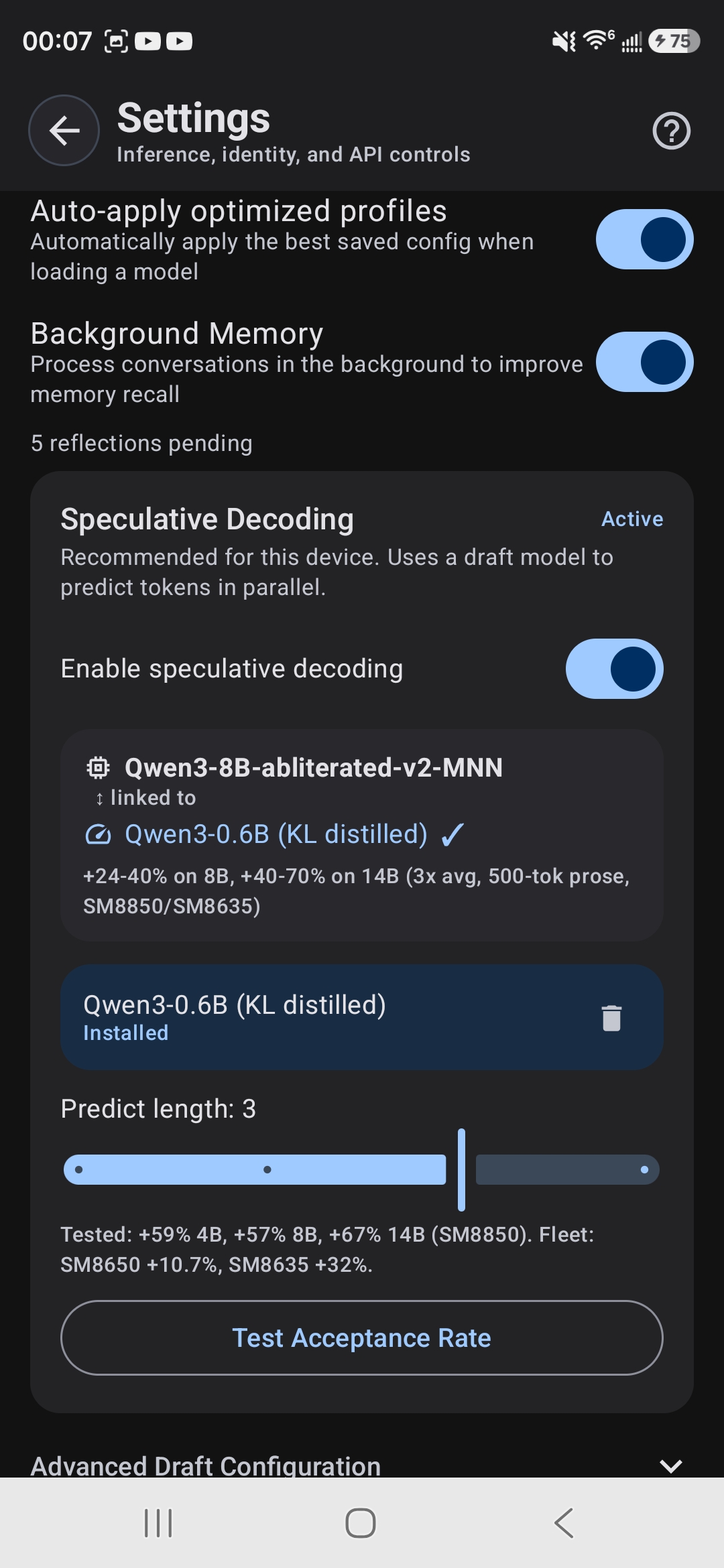
Spec decode is enabled by default on compatible models on supported hardware. But you have full control:
- Enable or disable spec decode globally in Settings
- Enable or disable per-model in the model card
- See a live indicator in the chat toolbar when spec decode is active
Auto-Detection & Optimization
TokForge automatically profiles your device on first launch to determine the best spec decode configuration. During profiling, it:
- Detects your SoC and available GPU acceleration paths
- Tests which draft-target model pairs work best for your hardware
- Measures actual speedups on your device
- Disables spec decode on devices where it wouldn't provide a benefit
This profiling happens automatically in the background using ForgeLab's optimization pipeline. No manual tuning required. The system "just works" on supported hardware.
Supported Models
Which Models Work?
Speculative decoding works best with larger language models. Currently, the Qwen3 family has first-class support for spec decode acceleration.
Other model families may be added over time as we optimize draft-target pairings. Check your model card in the app for the Spec Decode badge. If it's there, spec decode is available for that model.
What the Badge Means
When you see the Spec Decode badge on a model card, it means:
- TokForge has verified this model works well with speculative decoding
- A compatible draft model has been identified and will download automatically
- On your device, if the hardware supports it, spec decode will be enabled by default
- You can toggle it on/off in settings at any time
Device Compatibility
Supported Devices
Full Support (Best Results):
- Snapdragon 8 Elite (SM8850): best performance with OpenCL acceleration
- Snapdragon 8 Gen 3 (SM8650): full support with OpenCL acceleration
Early Support (Optimization Ongoing):
- MediaTek Dimensity 9400+: supported with Vulkan for 8B, CPU for 14B
Speculative decoding is designed for flagship mobile chips that have sufficient parallel processing power. On older or lower-end devices, TokForge automatically disables it to avoid slowdowns.
Automatic Enable/Disable
TokForge automatically detects compatibility. On your first launch, the app profiles your device to determine where spec decode helps. On supported hardware, it's enabled by default. On devices where it wouldn't provide a benefit, it's automatically disabled, because we don't want slower inference.
You can always manually override this in Settings if you want to experiment.
Multiple Backends
Speculative decoding works across multiple GPU paths:
- MNN OpenCL: Primary path on Snapdragon devices with Adreno GPUs (SM8850, SM8650)
- MNN Vulkan: Preferred for MediaTek Dimensity 9400+ with Mali GPUs on 8B models
- GGUF Vulkan CoopMat: Alternative Vulkan path with cooperative matrix optimizations
- MNN CPU: Used for larger models or when GPU paths aren't optimal (e.g., Dimensity 14B runs on CPU)
- GGUF backend: Alternative quantization format with spec decode support
The optimal path is selected automatically based on your device's SoC and GPU architecture. TokForge's BackendCapabilityResolver detects your hardware during first launch and routes to the fastest available option without any manual configuration needed.
Vulkan AR-Only Limitation
Current: Vulkan GPU acceleration is optimized for autoregressive (AR) decoding only. Speculative decoding on Vulkan currently falls back to the slow slide-window path because the verify step requires M>1 batch support, which is not yet available on Vulkan.
Roadmap: A GEMM kernel for M=2-4 is planned to enable full speculative decode acceleration on Vulkan, bringing the performance benefits of spec decode to Mali GPU devices.
Real-world impact: On the D9400+ (OnePlus Ace 5 Ultra), AR-only Vulkan at 15.3 tok/s actually outperforms spec decode at 10.9 tok/s, so this is not a practical limitation on current flagship hardware.
Settings & Controls
Global Settings
In Settings → Performance, you'll find:
- Enable Speculative Decoding: Toggle spec decode on/off globally
- Auto-Enable on Compatible Hardware: Automatically enable spec decode on devices where TokForge detects it would help
Per-Model Configuration
On each model card, you can:
- See the Spec Decode badge if the model supports it
- Toggle spec decode for that specific model
- View which draft model is being used (shown in the pairing card)
Draft-Target Pairing Card
When a model has spec decode enabled, you'll see a pairing card showing:
- Target Model: The large, powerful model (e.g., Qwen3 9B)
- Draft Model: The small, fast model used to predict tokens
- Speedup Range: Expected performance gain on your device (e.g., "+16-99%" depending on SoC and model)
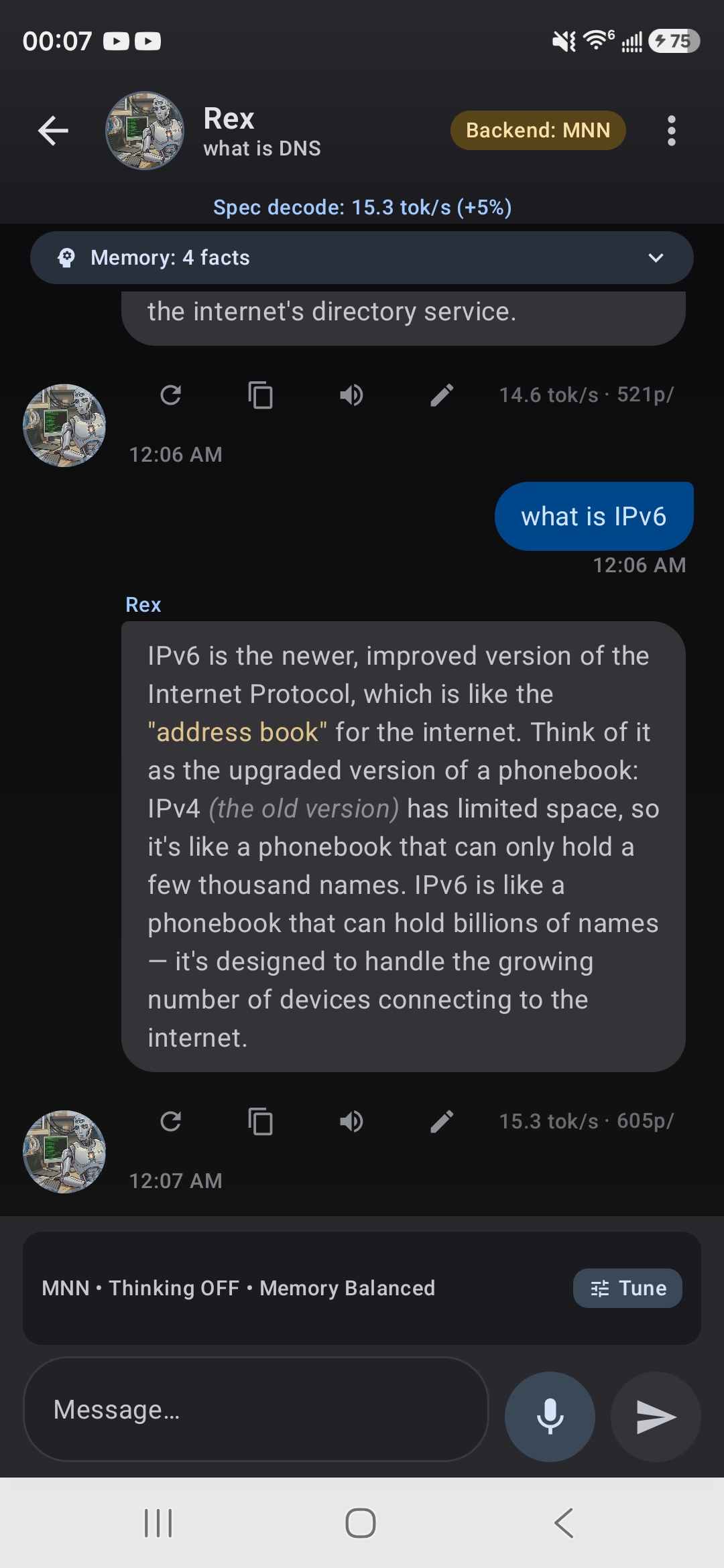
Live Speed Indicator
When spec decode is active and working, the chat toolbar displays a live speed metric showing tokens per second (tok/s) and the current speedup percentage. A icon appears during token generation to indicate that speculative decoding is actively accelerating your response. These metrics update in real-time as tokens are generated.
FAQ
Does speculative decoding affect output quality?
No. Output quality is identical with or without spec decode. The draft model proposes tokens; the main model verifies and accepts or rejects them. Only tokens that pass verification are included in your response. You get the exact same output, just much faster.
Does it use more RAM?
Yes, a small amount. The draft model stays in memory alongside the main model. Typically, this adds 10-20% to your memory footprint, depending on draft model size. On devices with memory constraints, you can disable spec decode to reclaim that RAM.
Can I disable speculative decoding?
Absolutely. You can disable it globally in Settings, or disable it per-model on the model card. If you find spec decode isn't helping on your device, turn it off.
What if my device doesn't support spec decode?
TokForge automatically detects this. If your device doesn't have the hardware for efficient spec decode, it will be disabled by default. Models will still download and run normally. Spec decode is purely optional acceleration. You can always manually enable it in Settings if you want to experiment.
How much disk space do I need for spec decode?
Draft models are lightweight and add minimal storage overhead. They download automatically as part of the Acceleration Pack, and you only need to store one draft model per target model. The total size is a small fraction of your main model.
Does spec decode work with custom quantizations?
Speculative decoding works with models quantized in MNN and GGUF formats. If you're using a custom model, spec decode may not be available, but the model will run normally without it.
Can I configure draft-target model pairs?
Not manually. TokForge automatically selects the best draft-target pairing for each model through comprehensive optimization testing (including ForgeLab's SpecDecodeSweepPlanner, which tests different configurations during AutoForge). The system finds the optimal pairing for your device. Custom pairings could result in poor performance, so trust the automatic selection for the best results.
Is there a performance penalty if spec decode fails to predict correctly?
No. Spec decode only helps if it succeeds. If the draft model predicts incorrectly, those tokens are rejected and re-computed correctly by the main model. There's no penalty. You just don't get a speedup for that particular token.
Do I need to download anything extra?
No. Draft models download automatically as "Acceleration Packs" when you download a compatible target model. You don't need to take any extra steps. It's all built into the normal download flow.
What's the battery impact?
Speculative decoding actually reduces battery consumption because inference is faster. Less time computing means less power draw. In most cases, spec decode will improve battery life compared to running without it.
Can I view detailed metrics for spec decode?
Yes. The chat toolbar shows real-time metrics including tokens per second and current speedup percentage whenever spec decode is active. For each response in your chat history, you can view detailed metrics by tapping the metrics icon, which shows tokens generated and the effective speedup for that particular response.